正式开始学习机器学习啦!!!
监督学习(Supervised)和无监督学习(Unsupervised)
监督学习回答的是“对于输入数据X能预测变量Y”,无监督学习回答的是“从数据X中能发现什么”。对于X,可能要回答“构成X的最佳6个数据簇都是哪些”或者“X中哪3个特征最频繁共现”
回归(Regression)和分类(Classification)属于监督学习的方法;类聚(Clustering)属于非监督学习的方法
监督学习中,若预测结果是一个连续的值,那么是回归(Regression),比如根据年龄,职业、性别预测工资;监督学习中,若预测结果是一个离散的值,那么是分类(Classification),比如区别男女,判断好坏。
聚类(Clustering)是一种无监督学习,它将类似的对象归到同一个簇中。有点像全自动分类。聚类方法可以应用所有对象,簇内的对象越相似,聚类的效果越好。聚类方法先并不知道任何样本的类别标号,希望通过某种算法来把一组未知类别的样本划分成若干类别。
聚类和分类最大的区别在于,分类的目标实现已知。聚类产生的结果和分类相同,只是类别没有预先定义。
通常,人们根据样本间的某种距离或者相似性来定义聚类,即把相似的(或距离近的)样本聚为同一类,而把不相似的(或距离远的)样本归在其他类。
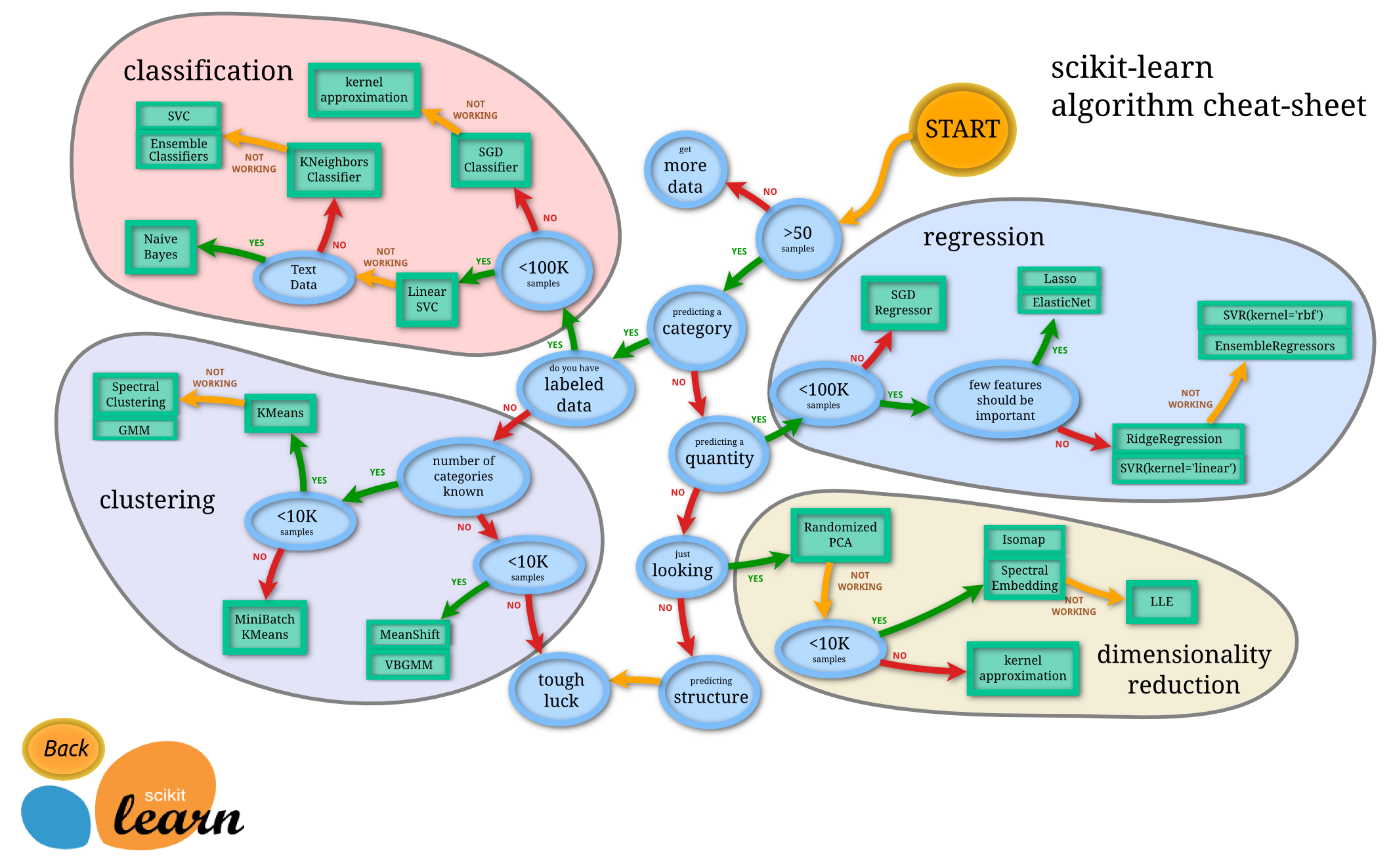
机器学习分类
classification (分类)
regression (回归)
clustering (聚类)
dimensionality reduction (降维)
给定一个样本特征 , 我们希望预测其对应的属性值 , 如果是离散的, 那么这就是一个分类问题,反之,如果是连续的实数, 这就是一个回归问题。
如果给定一组样本特征 , 我们没有对应的属性值 , 而是想发掘这组样本在 二维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
如果我们想用维数更低的子空间来表示原来高维的特征空间, 那么这就是降维问题。
聚类(clustering)
无监督学习的结果。聚类的结果将产生一组集合,集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异。
没有标准参考的学生给书本分的类别,表示自己认为这些书可能是同一类别的(具体什么类别不知道,没有标签和目标,即不是判断书的好坏(目标,标签),只能凭借特征而分类)。
聚类不属于监督学习,聚类问题解决的是给定一组样本,预测哪些样本之间离的更近,哪些样本之间离的更远,比如用户分群中,根据类别的定义,比如兴趣、购买力等,来将用户划分到多个类别中。分类(classification)
有监督学习的两大应用之一,产生离散的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。(即有目标和标签,能判断目标特征是属于哪一个类型)
分类属于监督学习,分类问题解决的是给定一个样本,预测变量是离散的,比如内容类别预测中,给定一个内容,需要预测出类别:体育、社会、财经等。回归(regression)
有监督学习的两大应用之一,产生连续的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断此人20年后今后的经济能力”的结果,结果是连续的,往往得到一条回归曲线。当输入自变量不同时,输出的因变量非离散分布(不仅仅是一条线性直线,多项曲线也是回归曲线)。
回归属于监督学习,回归问题解决的是给定一个样本,预测变量是连续的,比如股价预测中,给定一天的价格等信息,需要预测第二天的价格。
classification & regression
无论是分类还是回归,都是想建立一个预测模型,给定一个输入,可以得到一个输出。 不同的只是在分类问题中, 是离散的; 而在回归问题中是连续的。所以总得来说,两种问题的学习算法都很类似。所以在这个图谱上,我们看到在分类问题中用到的学习算法,在回归问题中也能使用。分类问题最常用的学习算法包括
SVM (支持向量机) , SGD (随机梯度下降算法), Bayes (贝叶斯估计), Ensemble, KNN 等。而回归问题也能使用 SVR, SGD, Ensemble 等算法,以及其它线性回归算法。
clustering
聚类也是分析样本的属性, 有点类似classification, 不同的就是classification 在预测之前是知道的范围, 或者说知道到底有几个类别, 而聚类是不知道属性的范围的。所以 classification 也常常被称为 supervised learning(有监督学习)分类和回归都是监督学习, 而clustering就被称为unsupervised learning(无监督学习)常见的有聚类和关联规则。
clustering 事先不知道样本的属性范围,只能凭借样本在特征空间的分布来分析样本的属性。这种问题一般更复杂。而常用的算法包括 k-means (K-均值), GMM (高斯混合模型) 等。
dimensionality reduction
降维是机器学习另一个重要的领域, 降维有很多重要的应用, 特征的维数过高, 会增加训练的负担与存储空间, 降维就是希望去除特征的冗余, 用更加少的维数来表示特征.降维算法最基础的就是PCA了, 后面的很多算法都是以PCA为基础演化而来。
scikit-learn
Supervised Learning 监督学习
已有样本数据(TrainingSet)包括输入(Input)和输出(Output),使用样本数据训练(Train)模型函数(Model),最后把未知输入(UnknownInput)带入模型函数,预测(Predict)输出(Output)
监督学习过程如下:TrainingSet(Input & Output) -> Train -> Model -> Predict(UnknownInput -> Output)
即训练集(包含输入和输出)-> 训练 -> 模型 -> 预测(未知输入-> 输出)